In 2017 lanceerde Google Ads Data Hub (ADH) als een privacy-veilige omgeving voor adverteerders en bureaus om te werken met gegevens op gebruikersniveau. First party data uit andere bronnen, zoals een CRM-systeem of een marketingdatabase, kunnen daarin ook worden opgenomen. Als vroege alfapartner heeft Annalect geholpen bij het vormgeven van dit product en zagen we al snel de toegevoegde waarde van zowel de hoeveelheid gegevens die beschikbaar is via Ads Data Hub als de brede reeks analyses en aangepaste queries die mogelijk zijn. Hoewel de uitrol van ADH geruime tijd heeft geduurd en het nog niet door alle adverteerders gebruikt wordt, hebben wij bij Annalect de mogelijkheid gehad om voor verschillende klanten met de oplossing te werken. Graag delen we onze ervaring met het gebruik van ADH voor Multi-Touch Attribution (MTA) analyses.
Aanpassen aan privacybeperkingen
Toen Google in 2018 de user ID’s verwijderde uit de Data Transfer Files binnen Europa, werden veel MTA-oplossingen, inclusief degene die wij hadden ontwikkeld, niet meer bruikbaar. Zonder de user ID’s waren we namelijk niet meer in staat om te bepalen welke gebruikers welke contacten met advertenties hadden, zoals impressies, clicks en interacties. Gelukkig bood ADH een nieuwe mogelijkheid om deze analyses voor onze klanten uit te blijven voeren. We gaan in dit blog in op twee belangrijke uitdagingen die ADH voor MTA analyses met zich meebrengt. Om dit beter te begrijpen, verwijzen we je graag naar de theorie achter de Markov-chain methodiek die we hebben beschreven in een eerder blog van ons. De twee belangrijke uitdagingen zijn:
- AHD is puur gebaseerd op SQL-query’s: hoewel het gebruik van andere programmeertalen op de roadmap van ADH staat, is momenteel de enige manier om de gegevens in ADH te benaderen via SQL-query’s.
- Aggregatiebeperkingen: naast het verwijderen van user ID’s uit de data, retourneert ADH alleen resultaten als de aggregatie verwijst naar een bepaald aantal gebruikers. Voor impressies is de drempel 50 gebruikers en voor clicks en conversies is de drempel 10.
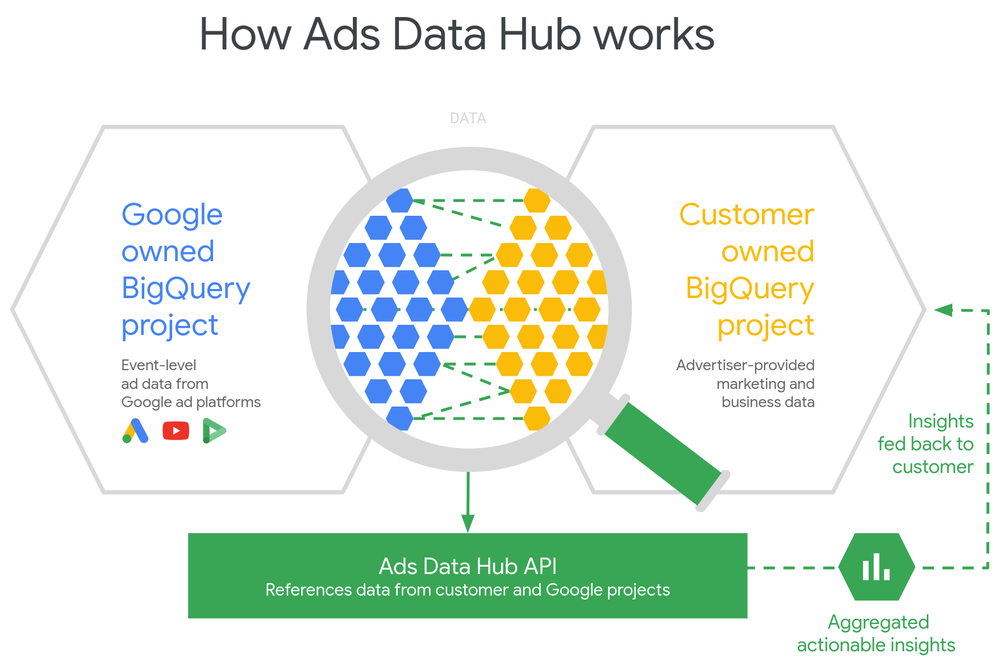
Een groot deel van deze uitdagingen kunnen worden opgelost. Onze eerdere methodologie was bijvoorbeeld gebaseerd op een databestand op gebruikersniveau dat gebruik maakte van een regressieanalyse. Hoewel het technisch mogelijk is om een regressieanalyse uit te voeren in een SQL-query, zou dit te omslachtig worden om mee te werken. Daarom hebben we onze methodologie vernieuwd, zodat er input nodig is die niet op gebruikersniveau, maar op het niveau van een contactpuntpad ligt. Een bestand op padniveau doorstaat de privacy controles van ADH en nadat we ze van BigQuery hadden gedownload, wisten we ze te analyseren met R of Python. Hoewel onze analyses niet langer gebruik maken van gegevens op gebruikersniveau, blijven de resultaten die we uit onze MTA analyses halen voor onze klanten nauwkeurig en impactvol. Met onze nieuwe methode zien we zelfs consistent een daling van de kosten per conversie van 10-30%!
Het einde van customer journeys
Jarenlang werd het bouwen en uitbreiden van datasets op gebruikersniveau beschouwd als een cruciaal onderdeel van het analyseren van customer journeys. Hoewel dit nog steeds het geval is voor mogelijkheden die voornamelijk gebruikmaken van first-party data (bijvoorbeeld website-optimalisatie), is dit voor MTA niet het geval. MTA, en attributie in het algemeen is namelijk sowieso afhankelijk van contactpunten buiten een eigen website doordat het uitgaat van advertising contacten in een ads omgeving. Het is de afgelopen jaren steeds moeilijker geworden om al deze contactpunten te volgen en ze per gebruiker op een volledige en consistente manier te verbinden. Mede doordat de consumer journey in de loop van de tijd complexer werd én dankzij het centraal stellen van privacy. De reis van de consument, in de meest gedetailleerde en individuele definitie, loopt dan ook ten einde.
Gelukkig hebben we dankzij data-cleanrooms zoals ADH niet alle onbewerkte gebruikersgegevens op logniveau nodig. Tijdens dit proces vroegen we ons af of de geaggregeerde output van ADH invloed had op de resultaten van onze MTA-analyses. Dus hebben we een experiment opgezet. Omdat Google de user ID’s nog steeds beschikbaar waren in de Verenigde Staten, konden we simulaties uitvoeren op die gegevens om aan te tonen dat de impact van de aggregatiebeperkingen beperkt is. Op basis van de resultaten hebben we enkele algemene vuistregels opgesteld over het analysevenster en het niveau van granulariteit, waardoor de aggregatiebeperkingen van ADH minimaal zijn.
De user interface van Ads Data Hub stelt ons in staat om queries handmatig uit te voeren of opnieuw uit te voeren, maar de echte kracht zit in de combinatie van de API en vooraf gedefinieerde queries. De API stelt gebruikers in staat om query’s te bouwen en uit te voeren, bijvoorbeeld vanuit R of Python. Voor gedefinieerde query’s kunnen worden ingesteld met parameters die kunnen worden aangepast door een API-aanroep. Dit maakt het proces van het uitvoeren van MTA-analyses voor onze klanten beter beheersbaar en minder foutgevoelig. Alles bij elkaar genomen vinden wij het niet erg dat gegevens op gebruikersniveau in attributieprojecten niet meer beschikbaar zijn. Sterker nog, we zijn blij met deze nieuwe technologie die ons in staat stelt om onze methodologieën te verbeteren en tegelijkertijd de privacy van de consument te respecteren.
Nieuwsgierig?
We komen graag met u in contact om te kijken wat voor u kunnen betekenen.